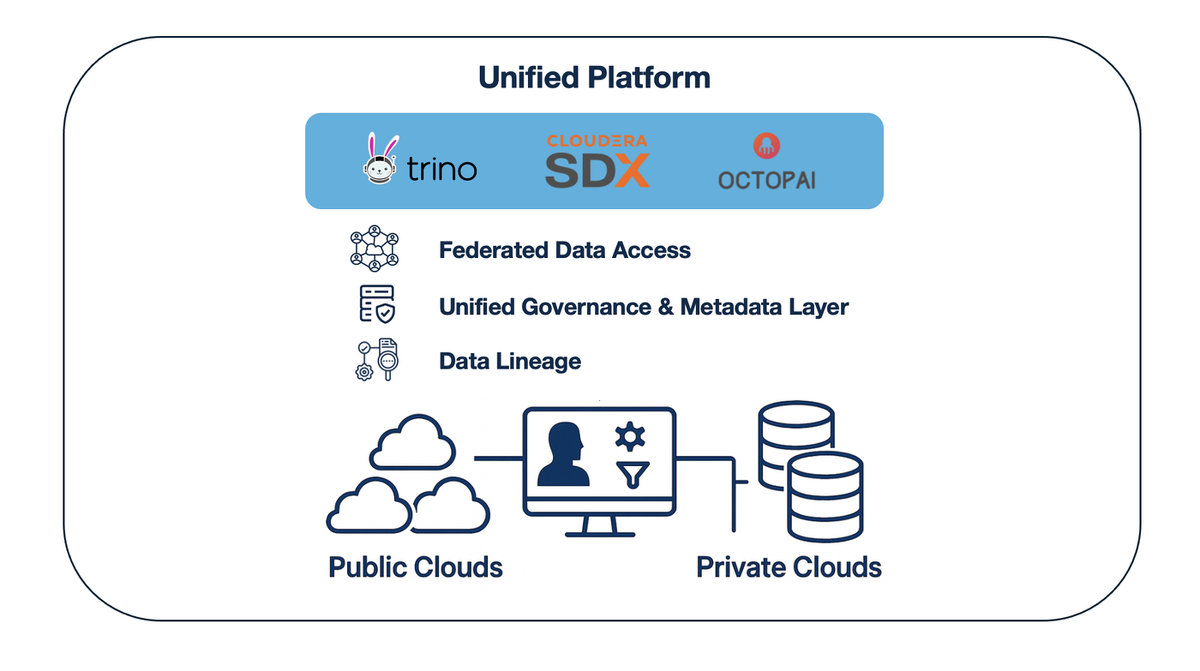
cloudera

Apache Spark has quickly grown into one of the major Big Data ecosystem projects and shows no signs of slowing down. In fact, even though Spark is well connected within the broader Hadoop ecosystem, Spark adoption by itself has enough energy and momentum that it may very well become the center of its own emerging market category.
In order to better understand Spark’s growing role in Big Data, Taneja Group conducted a major Spark market research project. They surveyed nearly seven thousand (6900+) qualified technical and managerial people working with Big Data from around the world to explore their experiences with and intentions for Spark adoption and deployment, their current perceptions of the Spark marketplace and of the future of Spark itself.
Adoption
The survey found that across the broad range of industries, company sizes, and Big Data maturities represented in the survey, over one-half (54%) of respondents are already actively using Spark. Spark is proving invaluable as 64% of those currently using Spark plan to notably increase their usage within the next 12 months. And new Spark user adoption is clearly growing – 4 out of 10 of those who are already familiar with Spark but not yet using it plan to deploy Spark soon.
Use Cases
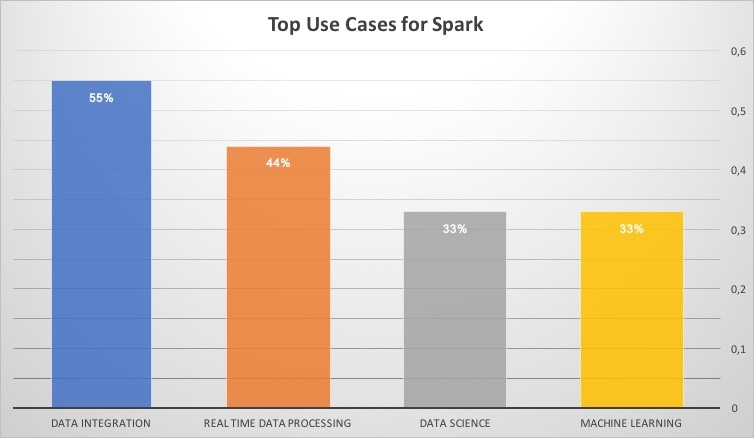
The top reported use cases globally for Spark include the expected Data Processing/Engineering/ETL (55%), followed by forward-looking data science applications like Real-Time Stream Processing (44%), Exploratory Data Science (33%), and Machine Learning (33%). The more traditional analytics applications like Customer Intelligence (31%) and BI/DW (29%) were close behind, and illustrate that Spark is capable of supporting many different kinds of organizational big data needs. The main reasons and drivers reported for adopting Spark over other solutions start with Performance (mentioned by 74%), followed by capabilities for Advanced Analytics (49%), Stream Processing (42%) and Ease of Programming (37%).
On Premise versus Cloud
Interestingly, while on-premise Spark deployments dominate today (more than 50%), there is a strong interest in transitioning many of those to cloud deployments going forward. Overall Spark deployment in public/private cloud (IaaS or PaaS) is projected to increase significantly from 23% today to 36%, along with a corresponding increase in using Spark SaaS, from 3% to 9%.
Challenges
The biggest challenge with Spark, similar to what has been previously noted across the broader Big Data solutions space, is still reported by 6 out of 10 active users to be the Big Data skills/training gap within their organizations. Similarly, more than one-third mention complexity in learning/integrating Spark as a barrier to adoption. Despite these reservations, we note that compared to many previous Big Data analytics platforms, Spark today offers a higher—and often already familiar—level of interaction to users through its support of Python, R, SQL, notebooks, and seamless desktop-to cluster operations, all of which no doubt contribute to its greatly increasing popularity and widespread adoption.
Conclusions
Overall, it’s clear that Spark has gained broad familiarity within the Big Data world and built significant momentum around adoption and deployment. The data highlights widespread current user success with Spark, validation of its reliability and usefulness to those who are considering adoption, and a growing set of use cases to which Spark can be successfully applied. Other Big Data solutions can offer some similar and overlapping capabilities (there is always something new just around the corner), but we believe that Spark, having already captured significant mindshare and proven real-world value, will continue to successfully expand on its own vortex of focus and energy for at least the next few years.
Source: Cloudera and the Taneja Group