

Big Industries Academy
Big Industries Academy
If you grow as an employee, the company grows as well. That’s why we decided to setup the Big...

Big Industries Academy
The Big Industries DNA
The Big Industries values, or in other words our DNA, are the fundamental beliefs upon which our...
Subscribe to our newsletter
Stay informed about our recent developments, newest projects and upcoming events


Big Industries Academy
Our Dream at Big Industries
“We will empower you to unleash your full potential
in a world of disruption and change”
...

Big Industries Academy
Why a Data Scientist is not a Data Engineer
I found an interesting article on O'Reilly.com ,written by Jesse Anderson, which explains the...

Big Industries Academy
10 proven steps to become a Data Engineer
A Data Engineer conceives, builds and maintains the data infrastructure that holds your...

Big Industries Academy
Hack the future 2018
Big Industries organizes already for the fourth time the Big Data Challenge during the Hack The...

Confluent
Kafka by Robin Moffatt (Confluent) and Big Industries
Join us for our next Brussels Apache Kafka® meetup on September 25th from 6:30pm, hosted...

Confluent
Apache Kafka vs. Enterprise Service Bus - Friends, Enemies or Frenemies?
Typically, an Enterprise Service Bus (ESB) or other integration solutions like...

Confluent
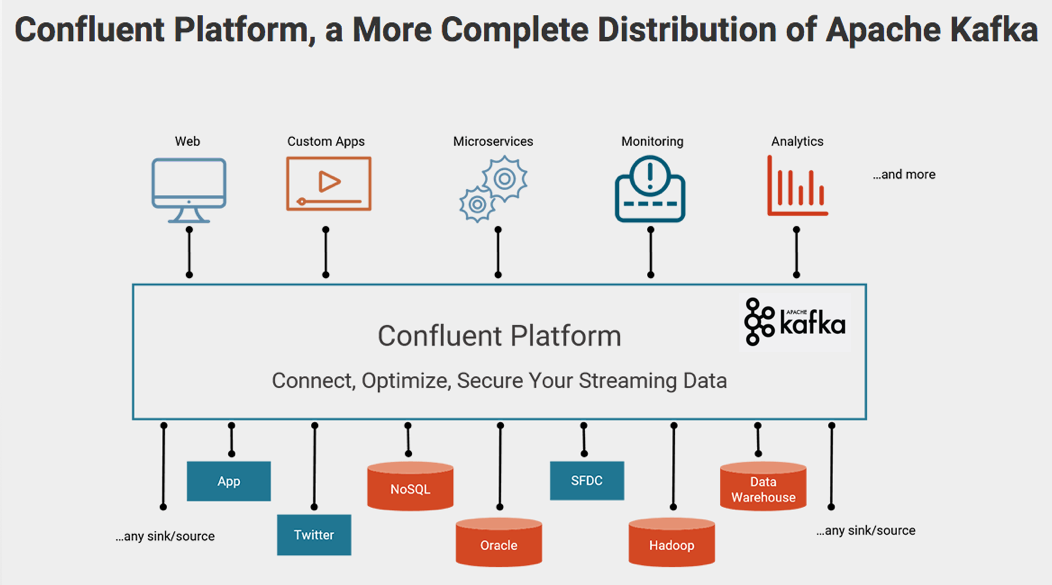
Apache Kafka: A distributed streaming Platform
Apache Kafka is a distributed streaming platform. What exactly does that mean?
A streaming...
Confluent
New Partnership with Kafka vendor Confluent
Big Industries recently entered into a partnership with Confluent.
Confluent, founded by the...