AWS

AWS Lake Formation is a service by Amazon that simplifies the building, securing and managing of Data Lakes, speeding up the process from months to just weeks. A Data Lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
Setting up and managing Data Lakes in a conventional way involves a lot of manual, complicated, and time-consuming tasks. This work includes loading data from diverse sources, monitoring those data flows, setting up partitions, turning on encryption and managing keys, defining transformation jobs and monitoring their operation, re-organizing data into a columnar format, configuring access control settings, deduplicating redundant data, matching linked records, granting access to data sets, and auditing access over time.
AWS Lake Formation – Simplifying Data Lakes
Creating a data lake with Lake Formation is as simple as defining data sources and what data access and security policies you want to apply. Lake Formation then helps you collect and catalog data from databases and object storage, move the data into your new Amazon S3 data lake, clean and classify your data using machine learning algorithms, and secure access to your sensitive data. Your users can access a centralized data catalog which describes available data sets and their appropriate usage. Your users then leverage these data sets with their choice of analytics and machine learning services, like Amazon Redshift, Amazon Athena, and Amazon EMR for Apache Spark. Lake Formation builds on the capabilities available in AWS Glue.
AWS Lake Formation: How It Works
AWS Lake Formation makes it easier for you to build, secure, and manage data lakes. Lake Formation helps you do the following, either directly or through other AWS services:
- Register the Amazon Simple Storage Service (Amazon S3) buckets and paths where your data lake will reside.
- Orchestrate data flows that ingest, cleanse, transform, and organize the raw data.
- Create and manage a Data Catalog containing metadata about data sources and data in the data lake.
- Define granular data access policies to the metadata and data through a grant/revoke permissions model.
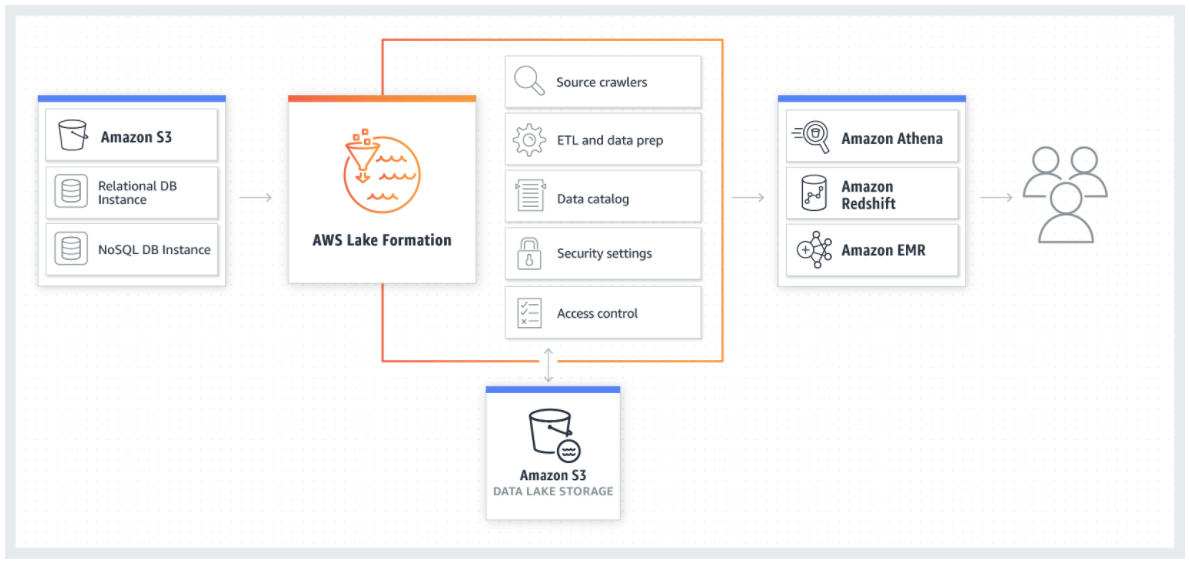
The following diagram illustrates how data is loaded and secured in Lake Formation.
As the diagram shows, Lake Formation manages AWS Glue crawlers, AWS Glue ETL jobs, the Data Catalog, security settings, and access control. After the data is securely stored in the data lake, users can access the data through their choice of analytics services, including Amazon Athena, Amazon Redshift, and Amazon EMR.
Conclusion
AWS Lake Formation significantly simplifies the process and removes the heavy lifting from setting up a Data Lake. Contact us If you are interested in learning about AWS Lake Formation in more depth, are curious about Amazon EMR support or are looking to see how Analogue.cloud has helped clients leverage AWS Lake Formation for Data Lake solutions.
Source: AWS Lake Formation Developer Guide