Confluent

Data streams can be processed on a record-by-record basis or over sliding time windows, and used for a wide variety of analytics. Information derived from such analysis gives companies visibility into many aspects of their business, (near) real time, making the organizational decision making processes multi-fold faster. Our engineers have deep expertise with designing, building and operating stream processing solutions.
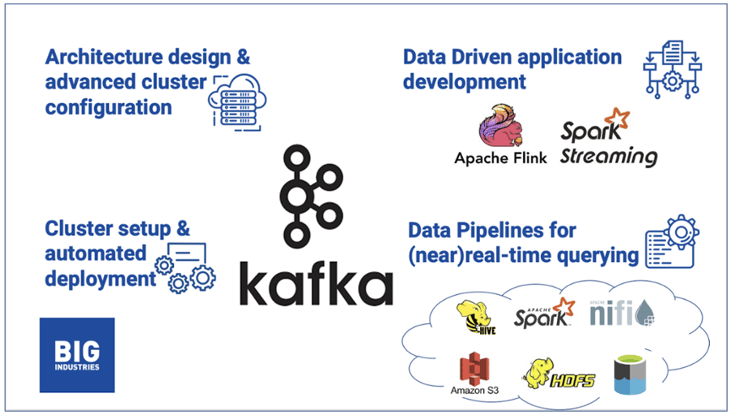
Architecture design & advanced cluster configuration
Our Architects analyse and qualify the Use Cases, identify the data sources, define the data ingestion strategy & acquisition, plan & design data storage and data processing pipelines, establish an information security strategy and choose different forms of data consumption outputs.
Cluster setup & automated deployment
Our DevOps engineers will help you with automating the deployment of your Kafka cluster on any platform. We use infrastructure-as-code tooling to deploy and manage Kafka clusters in the public cloud, as either a cloud-native service on Kubernetes or on bare metal and virtual machines.
Data Pipelines for (near) real-time querying
In the context of Apache Kafka, a streaming data pipeline means ingesting the data from sources into Kafka as it is created and then streaming that data from Kafka to one or more targets. By implementing a streaming data pipeline we are able to react to data as it changes, while it is current and relevant. And this in contrast to the batch world where we wait a period of time before collecting a set of data and then sending it to the target. Furthermore, in a Big Data context, a streaming data pipeline spreads the processing load and avoids resource shortages from a huge influx of data.
Data Driven application development
Our Data Engineers develop Data Driven applications that operate in real-time on a diverse set of data, pulled from multiple different sources. Examples are the use of Machine Learning to make real-time recommendations to customers or detect fraudulent transactions. Or use Graph analytics to identify influencers in a community and target these with specific promotions or perhaps use spatial data to keep track of deliveries.

Note: special thanks to Joris Billen for his contribution to this blog post